

Why data capture is essential for Intelligent Automation

Intelligent automation lies at the heart of many business projects aiming to automate tedious administrative processes. It is the perfect technology to automate not only repetitive tasks, but cognitive (or thinking) tasks as well.
With cognitive automation, business systems can now read and understand documents to process them automatically and in real-time.
This is possible thanks to machine learning and other artificial intelligence techniques that form the core of intelligent automation or hyper-automation.
If you want to know more about this, you can find an introduction to cognitive automation here.
The three R’s of intelligent automation
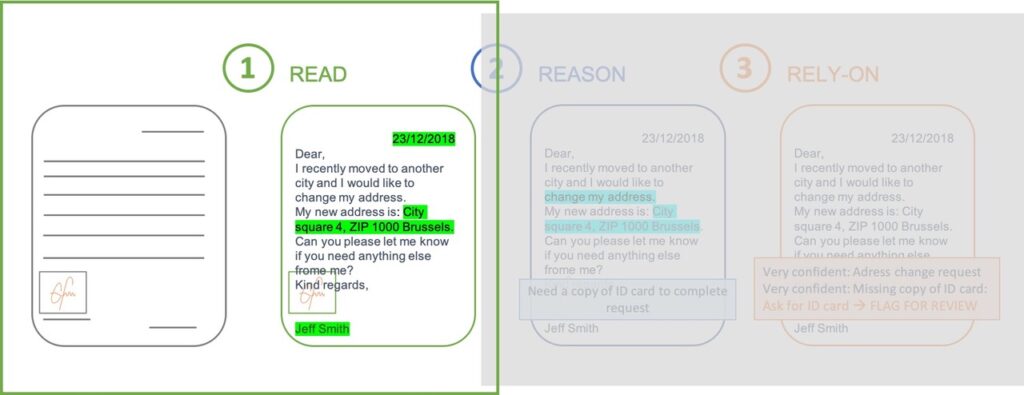
In our previous article, we summarized the technological foundations for Intelligent Automation in three easy to understand concepts: Read, Reason and Rely-on.

Read
The first step in the Intelligent Automation process is ‘READ’. For the cognitive automation tool to understand what it needs to do, it needs to be able to read the content of the document first. This is where OCR and data capture technologies set foot.
Reason
The second step entails the interpretation of the captured information from the document, like an email or image. This is accomplished through machine learning technologies. We will look at these techniques at greater length in our next article.
Rely-on
Finally, to truly automate your processes, you need a technology that can determine which documents still need to be looked at by an operator and which ones can go straight through processing.
On today’s menu: read
We will discuss the Reason and Rely-on concepts in a forthcoming article. First things first. In this article, we will zoom in on the first R of Intelligent Automation: The R of Read. Let’s go!
In order to automate document workflows, the automation technology needs to apply reason to those processes. The hyper-automation solution can only do so when it truly understands the content of the documents it needs to process.
Often the off-the-shelf OCR solutions can’t retrieve (enough) information out of the documents, thus not giving sufficient or qualitative input to apply the next step in the process: Reason.
So, what makes a good data capture solution great?
The fundamentals of data extraction
OCR or Optical Character Recognition has been around for almost a century now. Nevertheless, the technology, as well as the definition of OCR, has evolved a lot over those decades.
We can identify two definitions: the ‘traditional’ definition and its ‘broader’, more recent usage. The traditional definition is to recognize characters in an image. More recently, the term OCR is increasingly used to include assigning meaning to the characters.
Step 1: OCR (from image to text)
So, what is OCR? Simply put, Optical Character Recognition is a technique to recognize which characters appear in an image. It is the translation of characters on paper to characters on a digital screen.
This technology is already quite advanced in recognizing typed documents, which were printed and then photographed or scanned. For the time being, recognizing handwriting remains a bigger challenge.
Text written by a computer is always identical and has a slight space between each character. In a handwritten text, words are often written in one pen stroke. Which makes it harder to recognize each character separately.
Below we exemplified what a scanned invoice looks like once it’s OCR’ed.
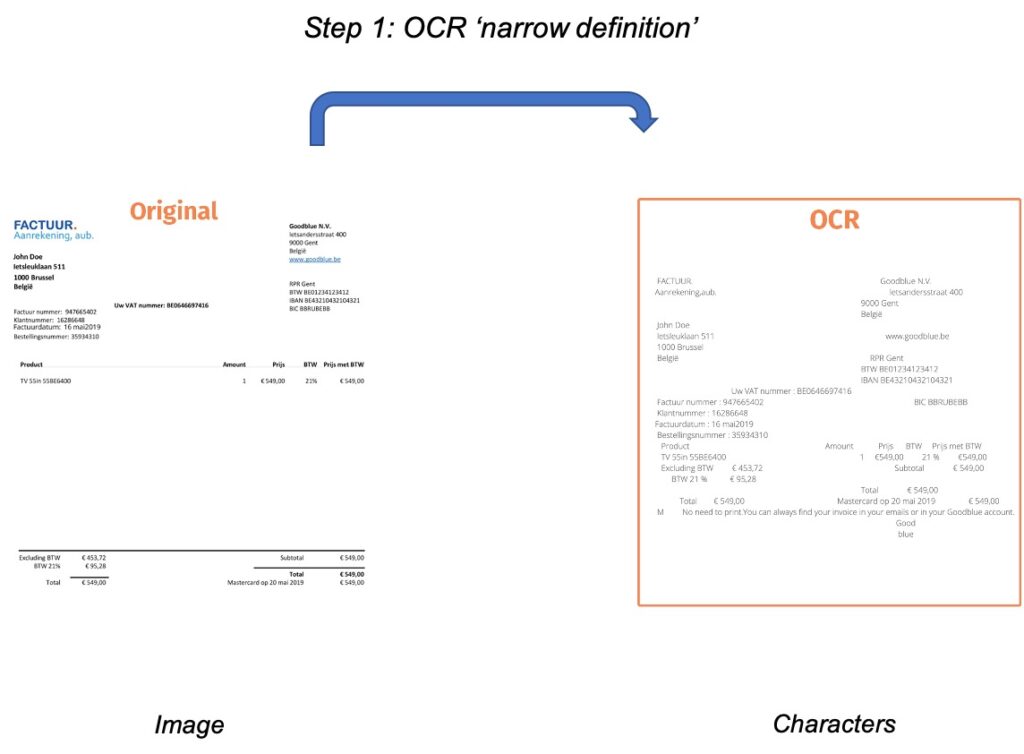
As you can see, it is quite challenging converting content without the structure of the original document. This is where the actual data extraction or information retrieval comes in.
Step 2: information retrieval (from text to information)
Now that the documents are digitized, it’s time to extract the relevant data from the digital letter soup. This is where the more advanced technologies come into play.
Let’s take a look at an example of an accounting firm. They are looking to gather information such as the invoice date, the total invoice amount, the IBAN, due date, etc.

First and foremost, this is where the technology needs to be able to distinguish an amount from a bank account number and a date from a structured message.
Secondly, when there are multiple occurrences of, e.g., an amount, it needs to determine which of those amounts is the total amount of the invoice. There are different ways to approach this challenge, so let’s take a look at the 3 main approaches to solve this data capture challenge.
The three methods of information retrieval
The capturing of data can only happen once the documents are digitized (with OCR technology). But how do you teach a computer which set of characters it should extract and which ones it should leave alone?
Template-based
The older data capture technologies often work with templates and location-based rules.
With a template-based solution, you would pick the top 50 suppliers and indicate where the information you wish to extract, is located on the document.
This then gets hard-coded by the data capture supplier in certain rule sets. They program their systems to, for example, always extract the value in the right bottom corner as the total amount.
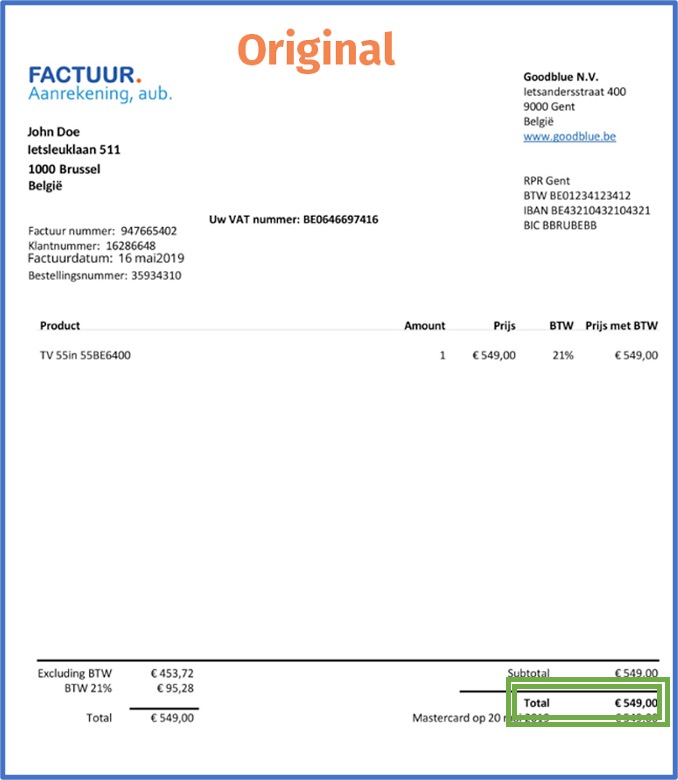
The limitations of this type of solution are that you can’t change suppliers and your current suppliers can never change the layout of their invoices. Since the technology was programmed to extract data from a specific location in the document.
Imagine the design changed and the value shifted 2 cm to the bottom, the technology will either no longer find a value to extract or it will extract another random value.
Keyword and pattern recognition
Another approach is to focus on patterns and keywords, this is done by programming RegEx’es or Regular Expressions.
For example, in invoice data extraction, you want to extract the total amount of an invoice.
So with this approach, you could write a rule (RegEx) that says to capture any amount that is in front or behind ‘€’, ‘EUR’, ‘euro’, ‘$’, ‘USD’, ‘Dollar’, etc.
However, there are usually multiple amounts on an invoice. So, which one do you pick for the total amount?
Or let’s say you wish to extract an IBAN number: in Belgium this is always preceded by ‘BE’, in the Netherlands by ‘NL’, and so on.
You can, therefore, program the technology to look for a series of 2 letters and 14 numbers following those letters. But sometimes there are multiple IBANs on the invoice. Which one is the correct one to extract?
The trouble is, you can’t really hard code rules that are smart enough to always capture the correct amount or the correct IBAN, making the performance of this technique limited.
Example: This is what a basic RegEx looks like. A rule which states: look for a series of characters where the first 2 characters are a value between A-Z and the next 14 characters are digits.
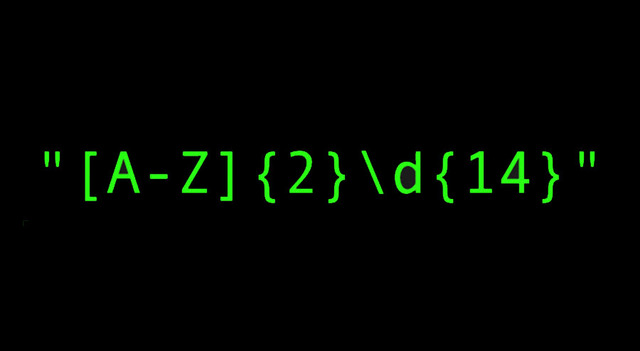
Another downside to this technique is that it is carved in stone. It is programmed with fixed rules and therefore, doesn’t improve in performance over time. If something changes (for example an extra digit for PO numbers), the code has to be adapted before it can retrieve the information.
AI-based
With location-based coding and regular expressions, you can already get a decent amount of information out of certain documents.
However, both techniques have their limitations. Firstly, capturing information from visual items (barcodes, logos, signatures, etc.) is not really in reach. The second and most important drawback is that these techniques are static. They don’t improve over time.
That is where AI-based solutions come in. With AI technologies at the core of the solution, there’s no longer a need to use hard-coded rules and fixed locations to capture the right date.
The machine learning technologies help the solution understand the documents and their content. There’s no special programming involved at the client’s side and the solution keeps evolving.
Below are two different AI techniques that can be used for data capturing purposes.
| Techniques/models | Explanation | Example |
| Computer vision models | These techniques detect and comprehend the visual aspects of the documents. | Detection of a logoSignature detectionBarcode detection |
| NLP or Natural Language Processing | These techniques focus on the textual aspects, like words and characters, and try to make sense of the content. | Leveraging the context of the different amounts in an invoice to identify the total amount |
There are a lot more things we could say about these (and other) techniques, but let’s not get carried away. We’ll dive deeper into these techniques in the article about the second R, Reason. For now, keep in mind that AI solutions learn from the feedback a user gives it.
For example, when it extracts the wrong value, the user can teach it which value it should have captured in the first place. This way, the AI technology recognizes it made a mistake and learns from it for the future.
The typical pitfalls in terms of data capture
By now you understand that there are a lot of different types of data capturing solutions out there. If you’re looking for a supplier for a data extraction carrier, there are some things you better look out for.
Don’t choose a solution that:
- is based on outdated technologies (template based or pattern recognition).
Most companies who’ve invested in those technologies a couple of years ago are now looking to replace them with more durable solutions. - only specializes in specific type of documents.
In our experience, most companies will want to apply the solution to other document types once they see the value of the solution on a first document type. - only captures information.
In today’s world, the focus is shifting towards automating processes from A-Z. Choosing a partner that can support you for all the steps in the Intelligent Automation process is crucial for a successful implementation of such a project.
About Contract.fit
At Contract.fit, our mission is to put Intelligent Automation at everyone’s fingertips.
We believe that AI and machine learning technologies can simplify our office life and free us from the burden of administrative tasks. With our solution, we want to help our clients increase customer satisfaction by freeing up their time for more value-adding, customer-focused tasks.
If you want to learn more about us and how we could help your business, don’t hesitate to reach out. Our experts are always happy to share their insights.
Leave a Reply