

Don’t ask for accuracy, ask for automation!

The ultimate goal of an intelligent automation use-case is to automate certain business decisions and lengthy back-end processes.
As introduced in an earlier article, there are 3 main components of intelligent automation:
- Read – Extracting data from documents
- Reason – Defining the next steps to process those documents (decisions such as: pay the invoice, forward request to correct department, flag fraud, etc.)
- Rely on – Trusting the AI-based decisions to automate the document handling process and free up time from human operators
In our “Read” article, we touched upon the advantages of AI-based data capture (or AI-based OCR) over traditional techniques.
In the “Reason” article, we explain the typical business challenges we solve with Machine Learning techniques to understand the context of and the language used in the document.
One of the most compelling questions in AI today, is how to make humans and machines work in symbiosis so that they each build on each other’s strengths and complement each other’s weaknesses.
In Intelligent Automation, value is created not by “getting predictions right”, but rather by also knowing when those predictions are right (and especially when they are not!). It’s all about trusting the machine, which brings us to our last R: Rely-on.
After reading this post, you’ll be able to explain the difference between ‘accuracy’ and (calibrated) ‘confidence’ and, more importantly, why the focus for AI models should shift from accuracy to automation.
Intelligent Automation: expectations versus reality
Customers today have higher standards for companies than 10 years ago. They expect instant user experiences: faster responses; shorter delivery times, more relevant and personalized offers, etc., all tailored to their needs.
This is why businesses are looking for AI technology solutions to help them automate time-consuming back-office processes. Their expectation is to boost the employee’s performance by leveraging human intelligence with artificial intelligence. But the reality today is that a 100% automation level of a task by AI is still very elusive.
The AI dream

Today there are many reasons why the expectations for this level of 100% automation are not realistic. Reasons include for example poor input quality, underestimation of the ambiguity of the problem, too many exceptions, or AI models which are not trained well enough, among others.
For example, let’s take a look at the 3 documents below. Everyone would agree that the 1st document is an invoice and the 2nd document a receipt. But what about the 3rd document, the parking fine? Is it an invoice, a receipt or yet something different?
In such a case, you’d want the AI to double-check with a human. This is also called an “edge-case”, or a situation in which it is not immediately clear whether to choose one class or the other.

The reality of AI today
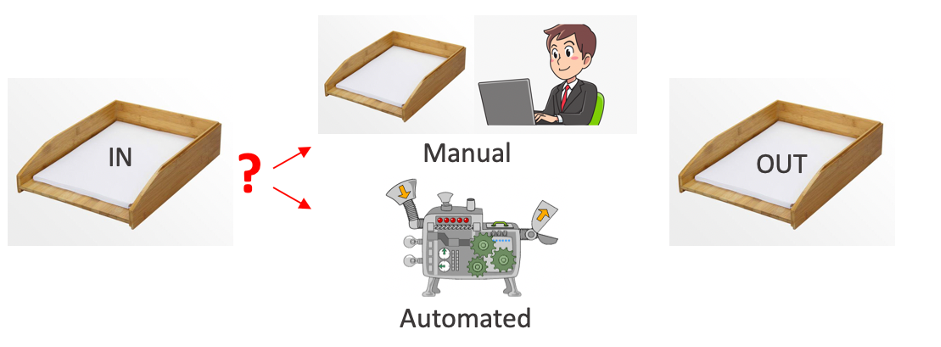
Whatever the reason, today, almost every solution needs a combination of humans and artificial intelligence. Some cases are easier for the machine to understand and automatically process. Others can be too complex, needing a human helping hand.
To prevent and avoid such AI-based automation pitfalls, it is crucial to determine which cases a human should verify manually.
The biggest misconception in Intelligent Automation
Many people talk about ‘Accuracy’ when they actually mean ‘Automation’. These are two different concepts. In what follows we will elaborate on the difference between both and why this is so important from a business perspective.
Why high accuracy rates alone won’t help you reach Intelligent Automation
Let’s start by answering the question what accuracy means for a cognitive automation use case. “Accuracy” describes how many predictions, of all the predictions the machine made, are correct or accurate when tested on unseen data.
So, when we say that the AI solution has a 90% accuracy rate, we’re saying that 10 out of 100 documents are incorrect. The accuracy is a property of any AI model.
“Automation” is defined as the % of cases that goes from IN to OUT via the automated flow. This is a choice that needs to be made.
Now the question is: how do you know which of those documents are the 10 documents a human operator should still verify for mistakes?
That’s where calibrated confidences come into the picture. Calibration implies having the model tone down or increase its prediction confidence. Sometimes it is underconfident while it is correct, other times it might be overconfident and incorrect, and thus in need of a correction in confidence.
Calibration implies changing the algorithms’ confidence to match its correctness. The machine needs to say with each prediction whether it is certain or not that it will be correct: this is a Yes / No flag. ‘Yes’ means a human still needs to check what the machine has predicted and correct if needed.
Let’s take a look at two AI models, which one would you prefer?
| Consider AI model A, 90% accuracy and no calibrated confidence flag. | Consider AI model B, 80% accuracy and with a well-calibrated confidence flag. |
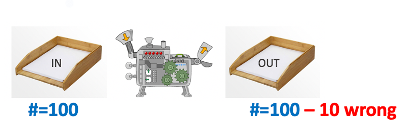 |  |
| Since there is no yes/no flag, you cannot choose which cases to look at; it’s all or nothing. 100% automation, but with 10% errors in the output | Flagged cases are looked at by a human operator. 80% automation, and no errors in the output |
Almost every company prefers model B: it best fulfils the automation need, even though it has lower accuracy. Model B brings significant business value, whereas model A does not!
Confidence levels in practice for Intelligent Document Processing
However, practically, how does the system know when to confidently flag a document for review or not? At Contract.fit, we do this by working with confidence scores.
A raw confidence score, or uncertainty, is a percentage (0-100%), that indicates whether the machine is not sure at all, somewhat sure or very sure about the correctness of a prediction. These raw scores are calculated by the different AI-models taking into account all sort of underlying features related to pattern, context, position or logical relations.
Every prediction has its own raw score: classification & splitting of documents, extraction of fields, extraction of line items and classification of line items. Various algorithms could then be applied to transfer the raw scores into a calibrated confidence score.
We have conducted in-house research to make our AI models more trustworthy, relaying calibrated confidences and giving them the ability to reliably communicate uncertainty. If you’re interested in reading more about the research, you can read our paper on predictive uncertainty for probabilistic novelty detection in text classification.
In the json output below, you can see a document prediction of with 94% calibrated confidence and a tax amount prediction with 95% calibrated confidence.
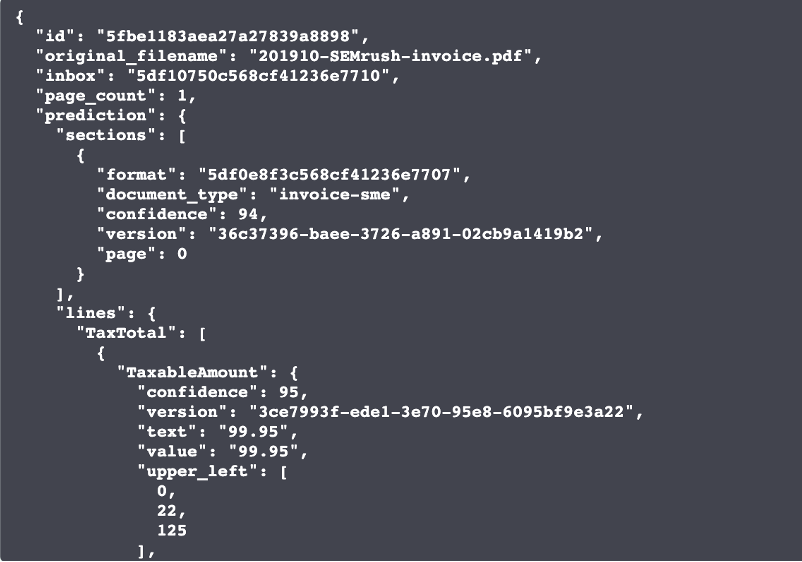
These individual confidence scores per prediction are used to set one confidence flag, or as we call it, a flag_for_review (FFR) at the document level. If True, the document is flagged for a manual review. If False, the document does not need a manual review and can go in full STP (Straight Through Processing).
What happens in the back is that the confidence score for each prediction is compared to the confidence threshold.
The confidence threshold is a setting that can be configured for each field individually. If for every prediction, the confidence score is higher than the threshold, the document does not need to be manually reviewed and the flag_for_review is set to False. This is the last field in the example above.
This makes it a lot easier for our users, as you don’t need to worry about each individual confidence level (even though it is still possible to review them in the json output). We take this burden away for our customers by ‘rolling up’ the confidence information in a flag_for_review.
In the Contract.fit Solution, confidence thresholds can be configured via the front-end. For our API-only clients, this can be consulted and patched via the corresponding API endpoint.

How to build a business case for your intelligent automation project
As illustrated above, the most important parameter for any intelligent automation business case is the percentage of automation, which is the driver for the savings potential. What is the percentage of automation we can achieve?
Or: “Out of 100 documents, how many do NOT need to be checked by a human?”
And how do you quantify the efficiency that can be realized with this automation. We do this, together with our customers, in two different ways:
- As an amount in staff costs if our customers would reduce the team.
- As an increased percentage of additional work that could be done, if they keep the same team.
We propose a calculation framework for such business cases, based on our large experience in this field. Get in touch if you want to apply it to your use-case: we’ll help to fill in the right parameters and you walk away with a detailed excel sheet.
About Contract.fit
At Contract.fit, we want to put Intelligent Automation at everyone’s fingertips. We believe that AI and machine learning technologies can simplify our office life and free us from the burden of administrative tasks. With our solution, we want to help our clients increase customer satisfaction by freeing up their time for more value-adding, customer-focused tasks.
Are you interested in seeing how confidences and intelligent automation can work for your document processing use case? Don’t hesitate to reach out. Our experts can help you get started with Intelligent Automation in your company!
Leave a Reply